Che cos'è l'agente utente di un browser?
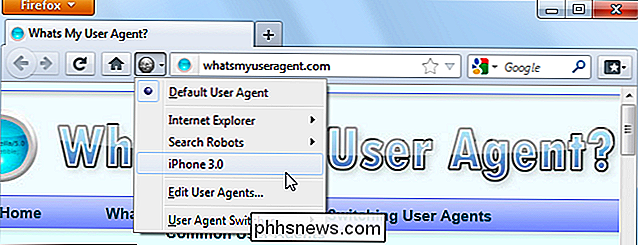
Il tuo browser invia il suo agente utente a ogni sito web a cui ti colleghi. Abbiamo già scritto su come modificare l'agente utente del browser in precedenza, ma che cos'è esattamente un agente utente, comunque?
Un agente utente è una "stringa", ovvero una riga di testo, che identifica il browser e il sistema operativo in server web. Sembra semplice, ma i programmi utente sono diventati un disastro nel tempo.
Nozioni di base
Quando il browser si collega a un sito Web, include un campo User-Agent nella sua intestazione HTTP. I contenuti del campo agente utente variano da browser a browser. Ogni browser ha il proprio agente utente distintivo. In sostanza, un agente utente è un modo per un browser di dire "Ciao, io sono Mozilla Firefox su Windows" o "Ciao, io sono Safari su un iPhone" a un server web.
Il server web può usare questo informazioni per servire diverse pagine Web a diversi browser Web e diversi sistemi operativi. Ad esempio, un sito Web può inviare pagine mobili a browser mobili, pagine moderne a browser moderni e un messaggio "si prega di aggiornare il browser" a Internet Explorer 6.
Esaminando gli agenti utente
Ad esempio, ecco l'agente utente di Firefox su Windows 7:
Mozilla / 5.0 (Windows NT 6.1; WOW64; rv: 12.0) Gecko / 20100101 Firefox / 12.0
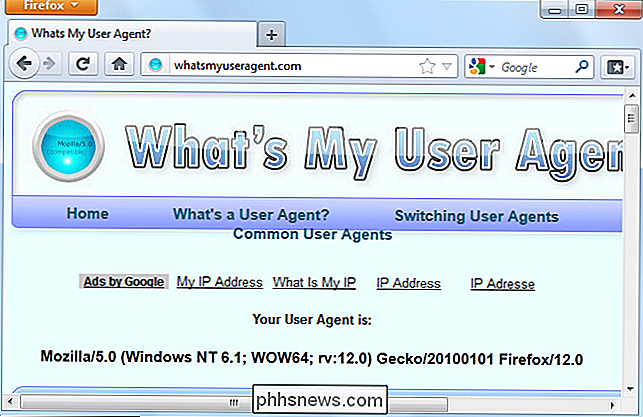
Questo agente utente comunica al server Web un po ': Il sistema operativo è Windows 7 (nome in codice Windows NT 6.1), è una versione a 64 bit di Windows (WOW64), e il browser stesso è Firefox 12.
Ora diamo un'occhiata all'agente utente di Internet Explorer 9, che è:
Mozilla / 5.0 (compatibile ; MSIE 9.0; Windows NT 6.1; WOW64; Trident / 5.0)
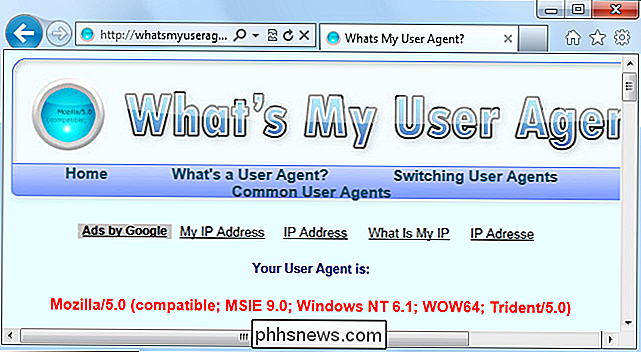
La stringa dell'agente utente identifica il browser come IE 9 con il motore di rendering Trident 5. Tuttavia, potresti notare qualcosa di confuso - IE si identifica come Mozilla.
Torneremo su questo in un minuto. Innanzitutto, esaminiamo anche l'agente utente di Google Chrome:
Mozilla / 5.0 (Windows NT 6.1; WOW64) AppleWebKit / 536.5 (KHTML, come Gecko) Chrome / 19.0.1084.52 Safari / 536.5
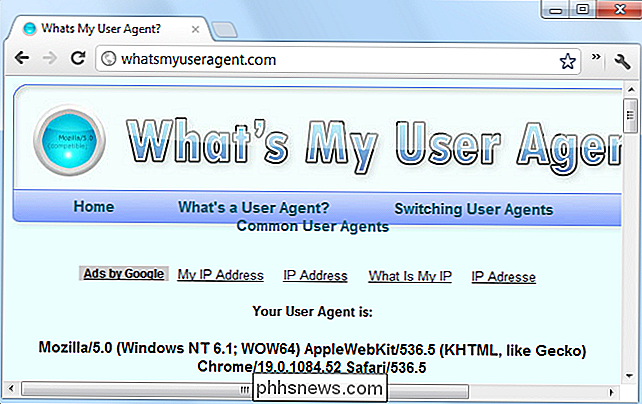
La trama si infittisce: Chrome è fingendo di essere sia Mozilla che Safari. Per capire il motivo, dovremo esaminare la cronologia degli user-agent e dei browser.
Lo User String String Mess
Mosaic è stato uno dei primi browser. La sua stringa user-agent era NCSA_Mosaic / 2.0. Successivamente, Mozilla è arrivato (in seguito ribattezzato Netscape) e il suo agente utente era Mozilla / 1.0. Mozilla era un browser più avanzato di Mosaic, in particolare supportava i frame. I server Web sono stati controllati per verificare che l'agente utente contenesse la parola Mozilla e abbia inviato pagine contenenti frame ai browser Mozilla. Ad altri browser, i server Web hanno inviato le vecchie pagine senza frame.
Alla fine, Microsoft Internet Explorer è arrivato e supportava anche i frame. Tuttavia, IE non ha ricevuto pagine Web con frame, perché i server Web li hanno appena inviati ai browser Mozilla. Per risolvere questo problema, Microsoft ha aggiunto la parola Mozilla al proprio agente utente e ha fornito ulteriori informazioni (la parola "compatibile" e un riferimento a IE). I server Web erano felici di vedere la parola Mozilla e hanno inviato a Internet le pagine Web moderne. Altri browser che sono venuti dopo hanno fatto la stessa cosa.
Alla fine, alcuni server hanno cercato la parola Gecko - il motore di rendering di Firefox - e hanno fornito ai browser Gecko pagine diverse rispetto ai browser più vecchi. KHTML - originariamente sviluppato per Konquerer sul desktop KDE di Linux - ha aggiunto le parole "come Gecko" in modo da ottenere anche le pagine moderne progettate per Gecko. WebKit era basato su KHTML - quando è stato sviluppato, hanno aggiunto la parola WebKit e mantenuto la linea originale "KHTML, come Gecko" a fini di compatibilità. In questo modo, gli sviluppatori di browser continuavano ad aggiungere parole ai loro agenti utente nel corso del tempo.
I server Web non si preoccupano realmente di quale sia esattamente la stringa dell'agente utente, controllano solo se contengono una parola specifica.
Usi
I server Web utilizzano agenti utente per una varietà di scopi, tra cui:
- Fornitura di pagine Web diverse a browser Web diversi. Questo può essere utilizzato per sempre, ad esempio per offrire pagine Web più semplici a browser meno recenti o malvagie, ad esempio per visualizzare un messaggio "Questa pagina Web deve essere visualizzata in Internet Explorer".
- Visualizzazione di contenuti diversi su sistemi operativi diversi, ad esempio visualizzando una pagina ridotta su dispositivi mobili.
- Raccolta di statistiche che mostrano i browser e i sistemi operativi utilizzati dai propri utenti. Se vedi statistiche di condivisione del mercato dei browser, ecco come vengono acquisiti.
I bot con crawling Web utilizzano anche i programmi utente. Ad esempio, il crawler web di Google si identifica come:
Googlebot / 2.1 (+ //www.google.com/bot.html)
I server Web possono offrire un trattamento speciale ai robot, ad esempio consentendo loro di passare attraverso schermate di registrazione obbligatorie. (Sì, questo significa che a volte puoi ignorare le schermate di registrazione impostando il tuo agente utente su Googlebot.)
I server Web possono anche dare ordini a bot specifici (o a tutti i bot) usando il file robots.txt. Ad esempio un server web potrebbe dire a un bot specifico di andare via, o dire a un altro bot di indicizzare solo alcune aree del sito web. Nel file robots.txt, i bot sono identificati dalle loro stringhe di user-agent.
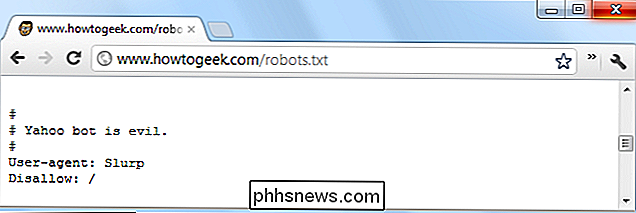
Tutti i principali browser contengono metodi per impostare i programmi utente personalizzati, in modo da poter vedere quali server Web inviano ai diversi browser. Ad esempio, imposta il browser desktop sulla stringa dell'agent user di un browser mobile e vedrai le versioni mobili delle pagine web sul desktop.
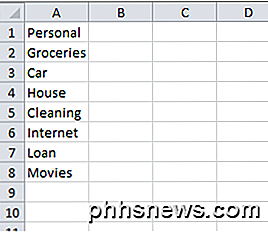
Creare elenchi a discesa in Excel utilizzando la convalida dei dati
Se sei un grande utente di Excel, allora potresti esserti trovato in una situazione in cui avresti potuto semplicemente scegliere un valore per una cella da un elenco a discesa di scelte piuttosto che dover copiare e incollare il testo tra le celle. Ad esempio, supponiamo di avere un foglio Excel per il tuo budget personale e ogni volta che inserisci una transazione su una nuova riga, digiti il suo reddito o una spesa.A v
Come condividere una cartella di rete da OS X a Windows
Esistono innumerevoli modi per copiare file tra computer, incluse fantastiche opzioni di sincronizzazione come Dropbox, ma se vuoi solo condividere uno dei tuoi cartelle dal tuo Mac al tuo computer Windows, puoi farlo facilmente. Naturalmente, se vuoi andare nella direzione opposta e montare una condivisione Windows sul tuo Mac, ti abbiamo anche coperto.